
행동대장 프로젝트 무중단 배포
사용성이 좋지 않다는 사용자 피드백에 따라 비즈니스 로직 개선
변경 전 서비스
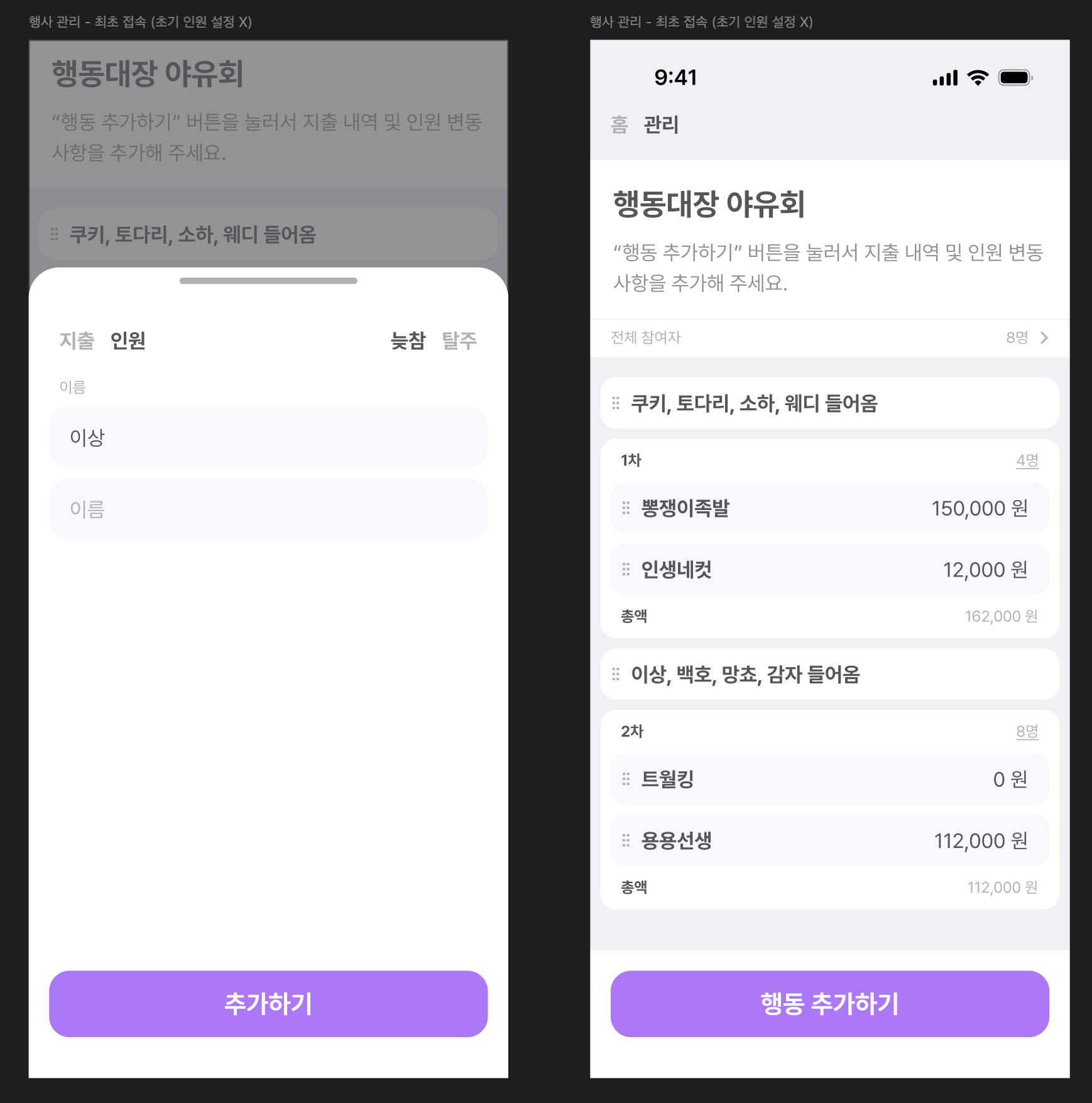 처음에 행동대장 서비스는 행사를 생성하고 참여 인원을 설정한 후에 지출 내역과 그 지출에 누가 참여했는지, 나갔는지 Commit log 처럼 쌓이도록 하여 인원 구성이 동일한 경우 차수 라는 개념으로 묶었다. 인원 변동이 없이 지출내역이 쌓이면 단순 N명의 인원으로 함께 지출한 금액을 나누면 된다고 생각했기 때문이다.
처음에 행동대장 서비스는 행사를 생성하고 참여 인원을 설정한 후에 지출 내역과 그 지출에 누가 참여했는지, 나갔는지 Commit log 처럼 쌓이도록 하여 인원 구성이 동일한 경우 차수 라는 개념으로 묶었다. 인원 변동이 없이 지출내역이 쌓이면 단순 N명의 인원으로 함께 지출한 금액을 나누면 된다고 생각했기 때문이다.
변경 후 서비스
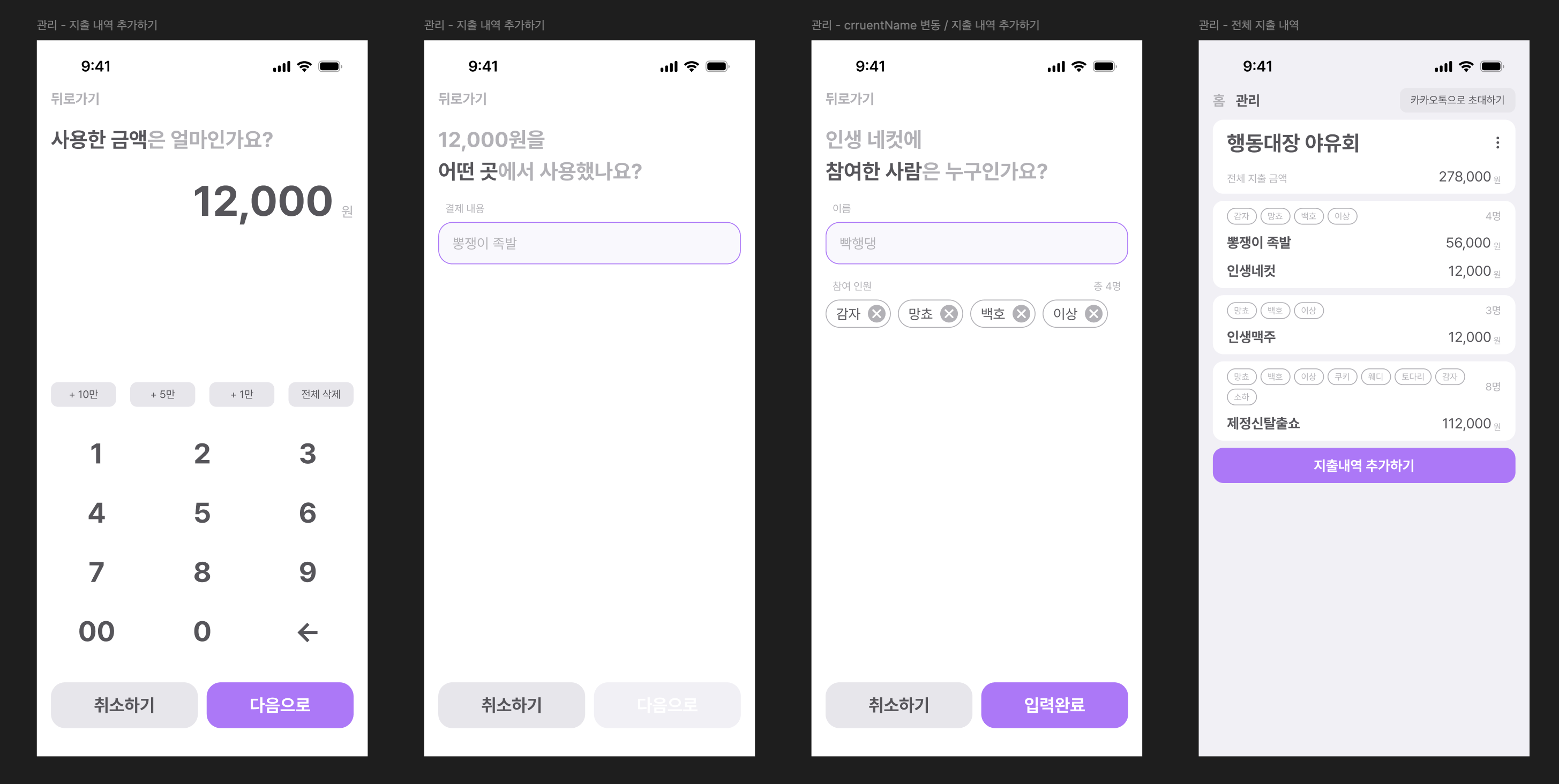 하지만 사용자들이 인원 변동을 어느 시점에 추가해야 하는지 정확히 이해하기 어렵다는 피드백을 반영하기 위해 백엔드, 프론트엔드 모두 기존 개발된 코드를 수정하여 보다 직관적으로 이해할 수 있도록 개선했다. 그렇다 보니 기존 데이터베이스의 스키마와 API에 변경이 생겨서 운영 중인 서버와 달라지는 상황을 맞이했다.
하지만 사용자들이 인원 변동을 어느 시점에 추가해야 하는지 정확히 이해하기 어렵다는 피드백을 반영하기 위해 백엔드, 프론트엔드 모두 기존 개발된 코드를 수정하여 보다 직관적으로 이해할 수 있도록 개선했다. 그렇다 보니 기존 데이터베이스의 스키마와 API에 변경이 생겨서 운영 중인 서버와 달라지는 상황을 맞이했다.
스키마의 변경이 필요한데, 운영 중인 서비스를 중단하지 않고 마이그레이션 해야 하는 상황
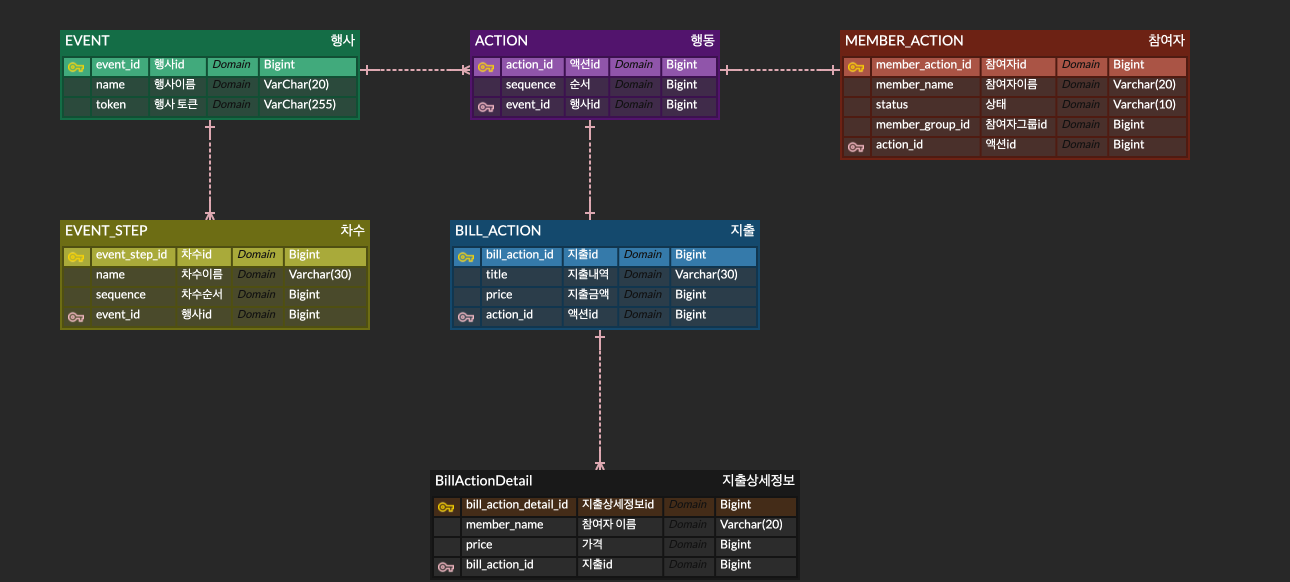
행동대장 프로젝트 진행 중 사용자가 서비스 로직을 잘 이해하기 힘들다는 피드백을 받아서 기존에 있던 개념인 행사 지출을 나타내는 BillAction, 행사 참여자의 출입내역을 나타내는 MemberAction을 제거하기로 했다.
기존 스키마
변경된 스키마
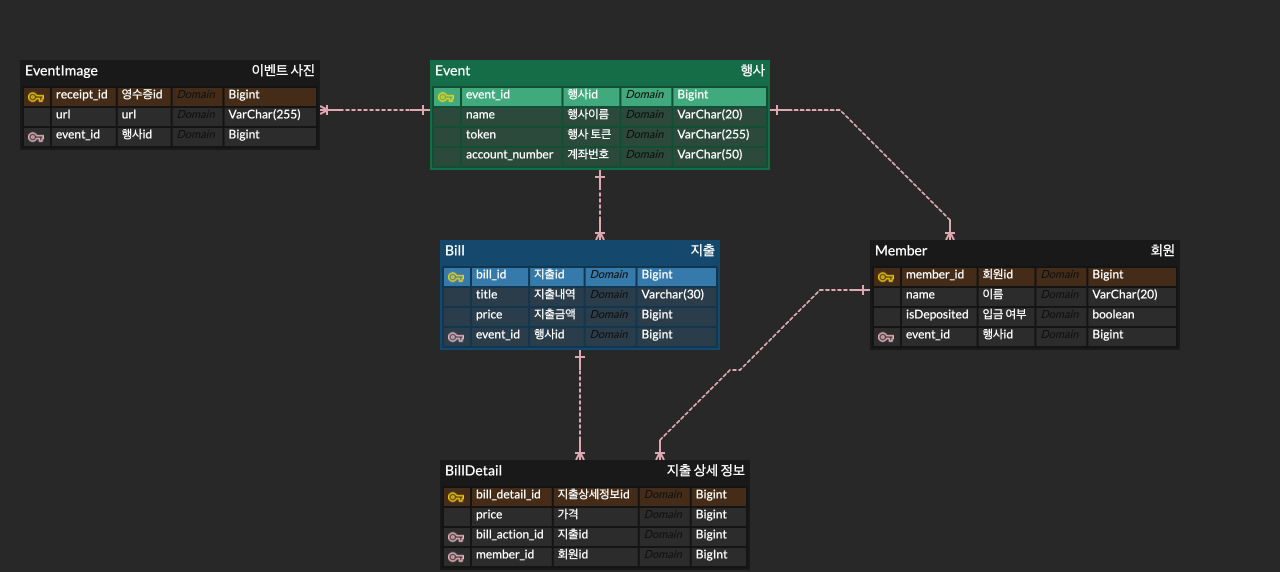
이에 따라 API와 스키마를 변경하게 되어 데이터베이스 마이그레이션을 해야 하는 상황이었다. 실시간 사용자가 많지는 않지만, 행동대장 서비스를 사용하는 사용자가 분명히 존재하기 때문에, 무작정 서버를 중단하고 스키마 변경 후 배포하는 빅뱅 전략을 선택하는 것은 옳지 않다고 생각했다.
서비스를 중단하지 않고 마이그레이션을 하기 위한 방법으로는 무엇이 있을까?
기존 테이블과 새로운 스키마의 테이블을 분리하여 운영한다.
기존 사용자는 v1 API를 통해 요청하고 새로운 사용자들은 v2 API를 통해 요청하도록 하여 하위 호환성을 보장한다. 그 후 사용자의 요청을 모니터링하여 구버전인 v1 API로 들어오는 요청이 더 이상 없는 것을 확인한 후 해당 API를 제거하여 서버를 중단하지 않고 점진적으로 마이그레이션 한다.
이 과정에서 각각의 테이블에 저장되는 데이터는 향후 최신 스키마 테이블에 모두 합쳐져야 하므로 ID가 겹치지 않도록 해야 한다. 그 방법으로는 두 테이블을 서로 다른 ID sequence를 사용하여 충돌이 발생하지 않게 한다. 예를 들어 v1 테이블은 ID가 1부터 시작했다면, v2 테이블은 10,000부터 ID를 시작하도록 하는 방법이 있다. 또 ID를 UUID로 변경하여 충돌 가능성을 낮추고, 두 테이블의 ID sequence를 고려하지 않고 간편하게 해결하는 방법이 있지만 UUID 특성상 데이터 크기가 크고, 인덱싱 성능에 영향을 미쳐 sequence를 다르게 하는 방법이 더 낫다고 판단했다.
고려할 상황으로 데이터베이스 마이그레이션 과정에서 v1 API 요청으로 저장되는 기존 테이블 A와 v2 API 요청으로 저장되는 새로운 테이블 B 간에 데이터 추가는 비교적 간단했지만, 실시간으로 두 테이블의 데이터를 수정, 삭제 요청을 동기화하여 데이터 일관성을 지키는 것이 복잡한 문제였다.
두 테이블 간의 데이터 동기화 문제를 해결하기 위한 방법으로는 이벤트 기반 동기화, CDC, 두 테이블 동시에 쓰는 전략 세 가지가 있다. 이벤트 기반 동기화와 CDC는 학습과 프로젝트 진행을 병행하기에 무리가 있다고 판단하여 고려하지 않았고, 두 테이블 동시에 쓰는 작업이 비교적 구현이 단순한 것이 장점이었기 때문에 후보로 선택했다. 하지만 두 테이블에 쓰기 작업이 모두 성공했을 때만 원자적으로 기록을 해야 하므로 두 테이블 중 한 테이블이 실패하면 성공한 테이블을 롤백해야 하는 복잡한 오류 처리 로직이 필요하다. 또 이와 같은 처리를 하나의 데이터베이스가 처리하다 보니, 성능이 떨어진다는 단점이 있다.
이 밖에도 메시지 큐를 사용하여 별도의 데이터베이스로 마이그레이션 하는 방법이 있었지만, 서비스의 규모가 크지 않고 사용자들이 점심, 저녁 시간에 집중적으로 사용하는 경향을 보였기 때문에 해당 시간대를 피해서 빅뱅 전략으로 Blue Green 방식의 무중단 배포를 하는 것이 인프라, 학습 비용 측면에서 현시점의 프로젝트에 합리적이라는 결론을 내렸다.
Blue Green 무중단 배포
행동대장 팀의 목표는 두 대의 서버를 대상으로 0에 가까운 다운타임으로도 배포할 수 있게 만드는 것을 목표로 했다. 무중단 배포 방식에는 대표적인 방식으로 Rolling, Blue Green, Canary 배포가 있는데,Canary 배포는 서버가 단 2대인 현재 서비스에 적용하기에 과하다고 생각했다. 그래서 Rolling과 Blue Green 배포를 중점적으로 고려했다.
현재 인프라 아키텍처는 AZ를 A와 B로 분리하고 Private Subnet에 EC2 한 대씩 두고, Public Subnet에 ALB가 위치한 구조다. Public Subnet에 논리적인 개념으로 하나의 ALB 두고 사용하여 EC2 2대에 요청을 분산하고 있다.
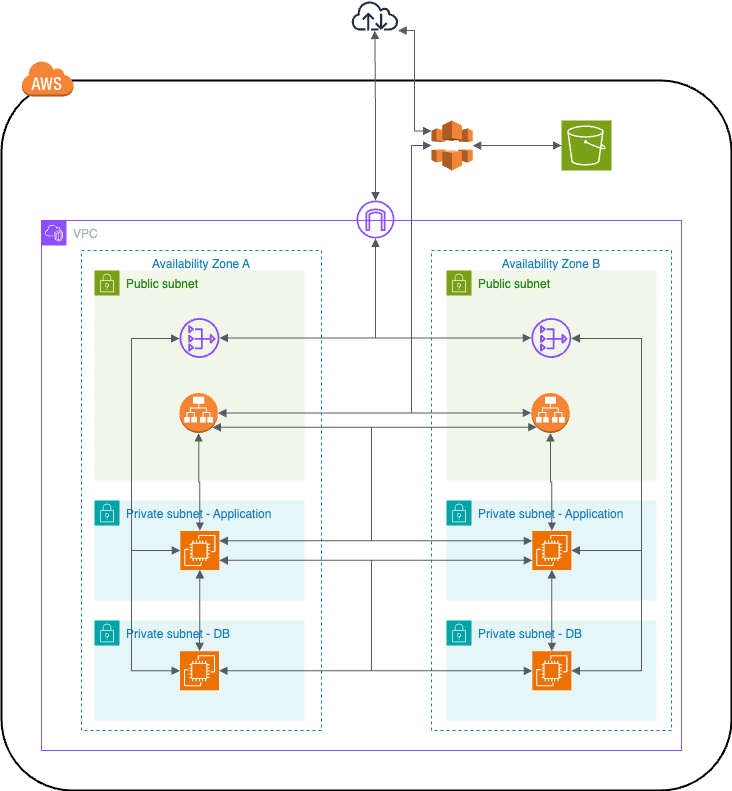
AWS ALB와 EC2 대상 그룹을 이용한 Blue Green 배포
이미 ALB를 사용하고 있기 때문에 AWS가 제공하는 EC2 Auto Scaling을 통해 EC2 대상그룹을 설정하여 Blue Green 배포를 하려 시도했다. 하지만 프로젝트 제한으로 보안그룹 권한이 주어지지 않아서 Auto Scaling 설정을 적용할 수 없었다. Auto Scaling 기능을 사용하지 않고 AWS CLI로 우회하여 배포 시점에, ALB에 Health Check를 임의로 조작해서 두 대의 EC2 중 한 대에 요청을 몰아주고, 요청을 받지 않는 EC2를 먼저 Rolling 배포하려 했지만, CLI를 통해 ALB에 접근할 수 있는 권한도 없었다. 그래서 Auto Scaling 설정 권한과 CLI를 통해 접근할 수 있는 권한을 요청하는 선택을 할 수도 있었지만, 팀원들과 논의해본 결과 현재 정책 내에서, 제한이 있는 상태에서 문제를 해결하는 경험을 해보기로 했다.
ALB와 EC2를 사용한 Rolling 배포
ALB는 뒤에 있는 두 대의 EC2에 각각 특정 시간 동안 특정 횟수만큼 Health Check 하여 서버가 정상적으로 실행되고 있다면 요청을 전달한다. Rolling 배포를 위해 먼저 한 대의 EC2 내에 구동 중인 Tomcat 프로세스를 중단하면, ALB는 해당 EC2의 Health Check에 실패한다. ALB는 실행 중인 EC2에만 요청을 전달하게 되고, 그사이에 다른 EC2에 새로운 애플리케이션을 배포하고 Tomcat 프로세스를 실행한다. 배포를 시도하는 하나의 EC2 내에서는 애플리케이션을 중단하고 기존과 같은 포트를 사용하여 새로운 버전의 애플리케이션을 실행한다. 이 과정을 순차적으로 EC2마다 진행하는데, 그림으로 표현하면 다음과 같다.
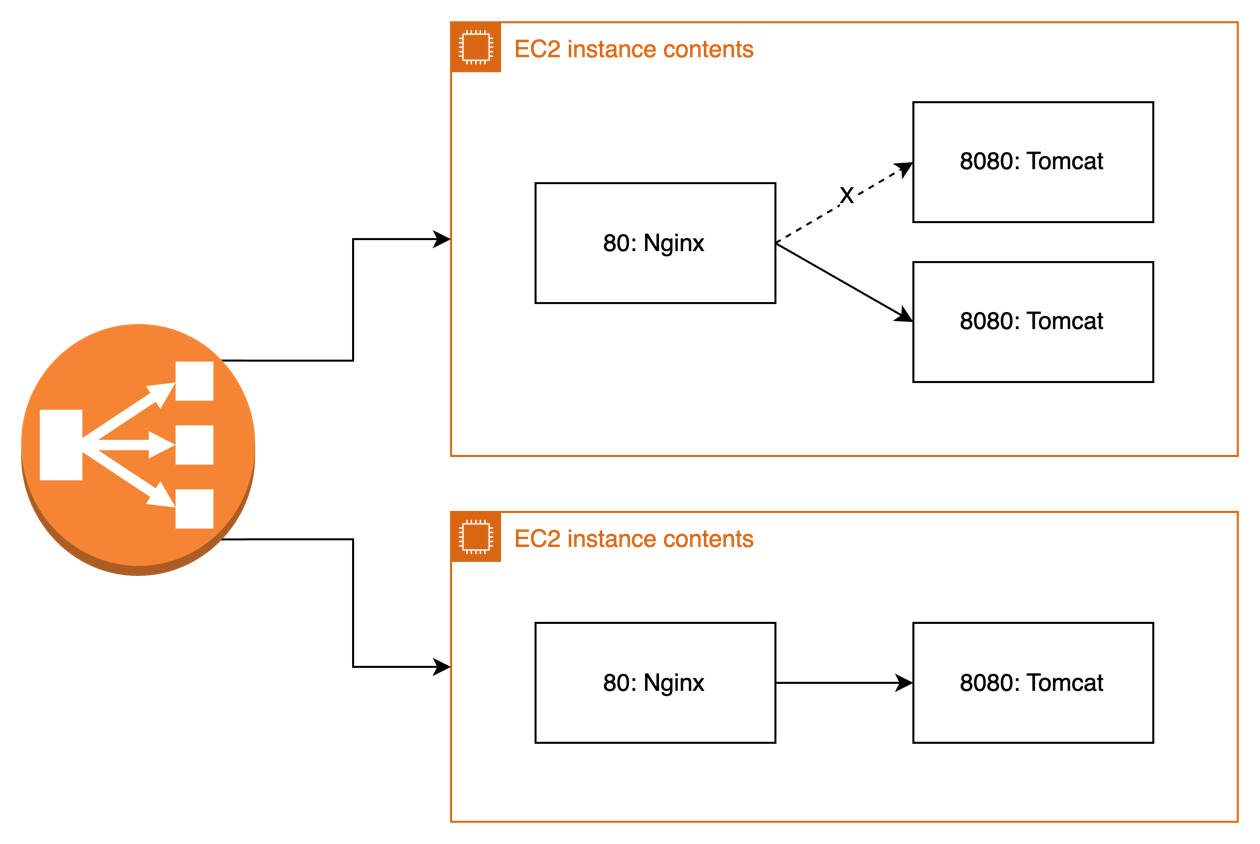
이 방식을 적용했을 때, 배포 중인 EC2 내부에서 기존 애플리케이션을 중단하고 새로운 애플리케이션을 실행하는 것과 동시에 ALB가 Health Check를 통해 서버의 중단을 확인하고, 배포 후 다시 정상 작동하는 것을 확인하는 동안 발생하는 다운 타임이 존재할 거로 생각했다. 사용자 요청이 얼마나 실패하는지 확인하기 위해 테스트를 진행했다. 테스트는 Jmeter를 사용해서 100명의 가상 사용자를 대상으로 배포 전부터 후 시간 동안 무한히 요청했다.
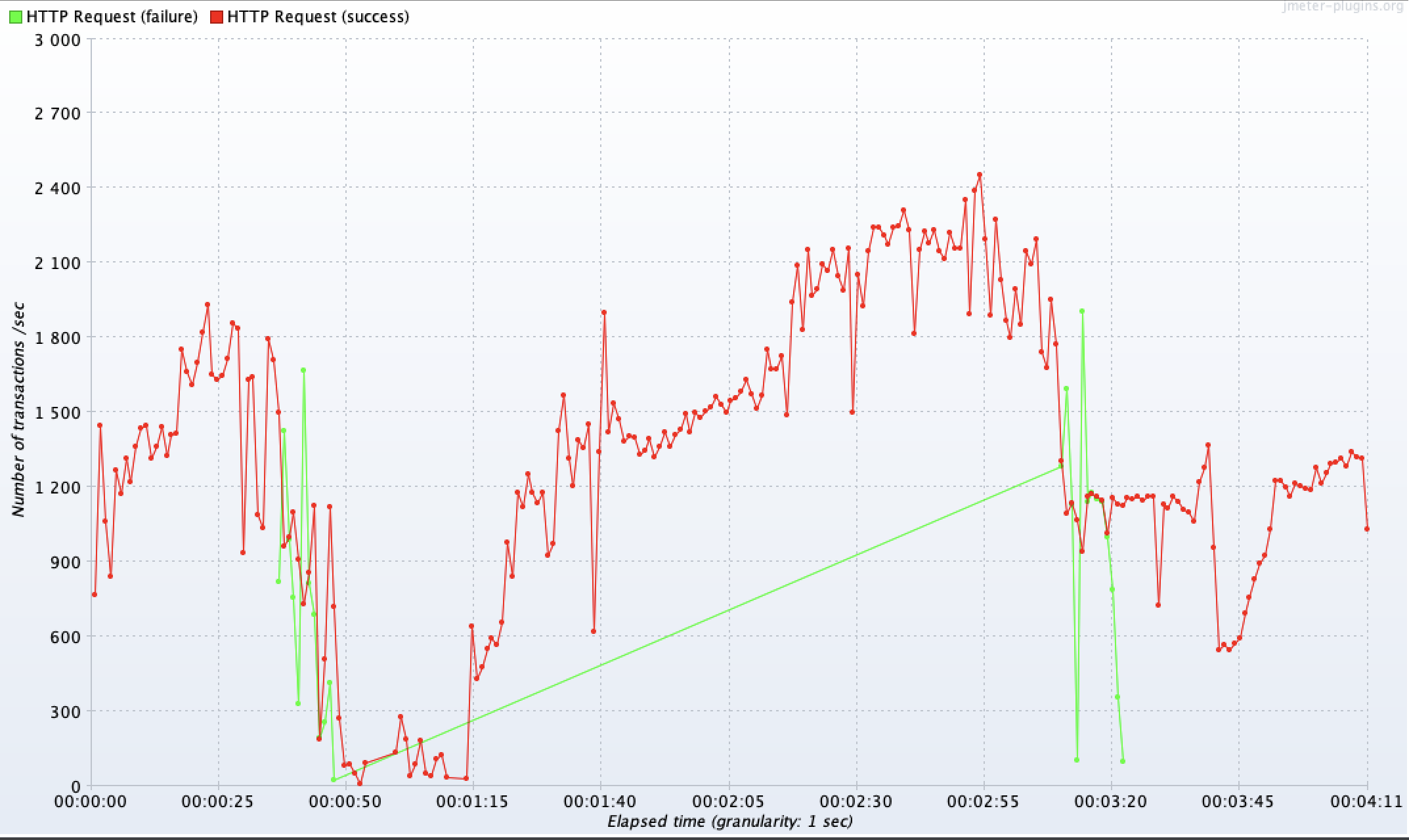
위 그래프는 하나의 점이 초 단위이며 초록색 점은 실패한 요청을 의미한다. 그림에서 상당히 많은 요청이 실패한 것을 볼 수 있다. 초록색 점 무리는 2번 있는데, EC2 두 대에 순차로 배포할 때 각각 다운타임 동안 실패한 요청 묶음이다. 위 그래프를 통해 하나의 EC2에 배포할 때 20초 정도의 다운 타임이 발생했고 한 번의 배포에 2개 EC2를 배포하기 때문에 총 40초의 다운 타임이 발생했다는 것을 확인할 수 있다.
분명 ALB가 Health Check를 통해 로드밸런싱하고 있고 각 EC2에서 롤링 배포하는데 무엇이 문제일까? 문제는 ALB의 Health Check에 있었다. ALB의 default Health Check 주기는 15초로 설정되어 있다. Health Check 한 직후 ALB는 EC2가 가용 상태라고 인식하고 들어오는 요청을 전달한다. 하지만 Health Check 한 직후 정상 동작한다고 판단한 사이에 배포가 일어나서 사실은 EC2가 중단된 상태가 되어 요청이 중단된 EC2로 전달되는 상황이 발생할 수 있다. 즉, 운이 나쁘면 15초의 다운 타임 동안 중단된 서버에 요청이 전달되고, 또 새로운 톰캣 프로세스가 실행되기까지 추가 시간이 걸릴 수 있다.
추가로 롤링 배포 방식은 스키마 변경으로 인해 하위 호환을 보장하지 못하는 배포가 필요한 상황에 적용할 수 없고, 일부 EC2에 부하가 커진다는 점이 단점이다. 2대의 EC2로 서비스를 운영하는 상황에서 Rolling 배포를 하게 되면, 남은 한 대의 서버가 모든 부하를 감당해야 하므로 현재 상황에서 안정적인 Rolling 방식의 배포를 하기 위해서는 1대의 서버를 추가하는 것이 적절하다고 판단했다. 판단 근거는 2대 EC2 상황에 Rolling 배포 시 남은 한 대의 서버에서 100% 요청을 감당해야 하고, 총 3대 EC2를 운영한다면, 한 대에서 배포해도 남은 2대에서 50%씩 요청을 처리하면 되기 때문에 남은 한 대의 EC2에서 문제가 생겨도 2대만을 운영하는 상황에서 발생할 수 있는 SPOF 문제에서 조금은 여유를 두고 대처할 수 있다.
Nginx를 사용한 Blue Green 배포
위 문제를 해결하기 위해 Nginx 도입을 결정했다.
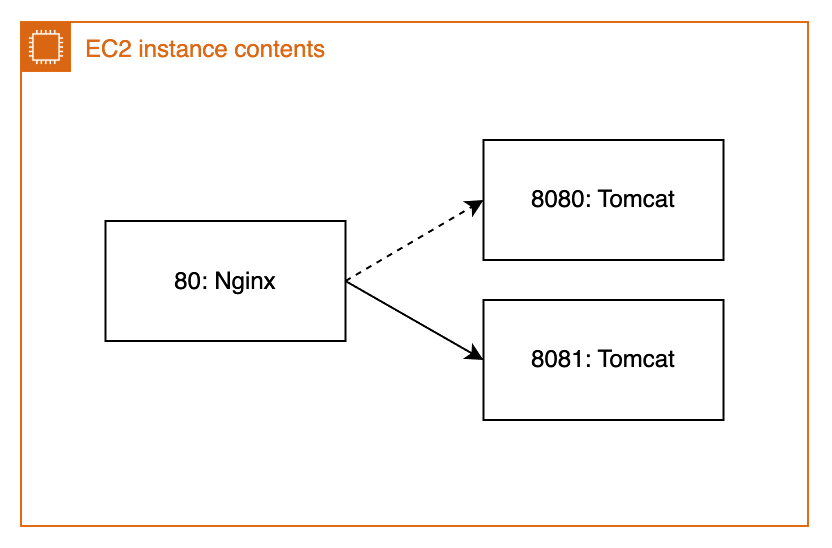
배포 전에는 80 포트로 연결된 Nginx 프로세스와 8080 포트로 연결된 Tomcat 프로세스가 실행 중이다. Nginx로 들어오는 요청은 8080 포트로 포트 포워딩한다. 배포가 시작되면, 새로운 Tomcat 프로세스를 실행하고 8081에 연결한다. 이후에 Nginx의 80 포트로 들어오는 요청을 기존 8080 포트 대신 8081 포트로 연결한다.
Nginx를 사용하면 얼마의 다운 타임이 발생할까?
Nginx의 설정을 변경할 때 변경한 설정을 적용하기 위해 Reload 해야한다. 문제는 Reload 하는 동안 사용자 요청을 받지 못하는데, Nginx Reload 시간은 밀리초 단위 찰나의 순간이다. 정확히 Reload 하는 순간에 들어온 요청은 정상 응답하기 어렵지만, 현재 서비스 규모와 트래픽을 고려했을 때 이 정도 다운 타임은 사용자 경험에 크게 영향을 미치지 않을 거라 판단했다.
다운 타임이 얼마나 발생하고, 사용자 요청이 얼마나 실패하는지 확인하기 위해 테스트를 진행했다. 테스트는 Jmeter를 사용해서 100개의 동시 요청을 배포 전부터 후까지 무한히 반복했다.
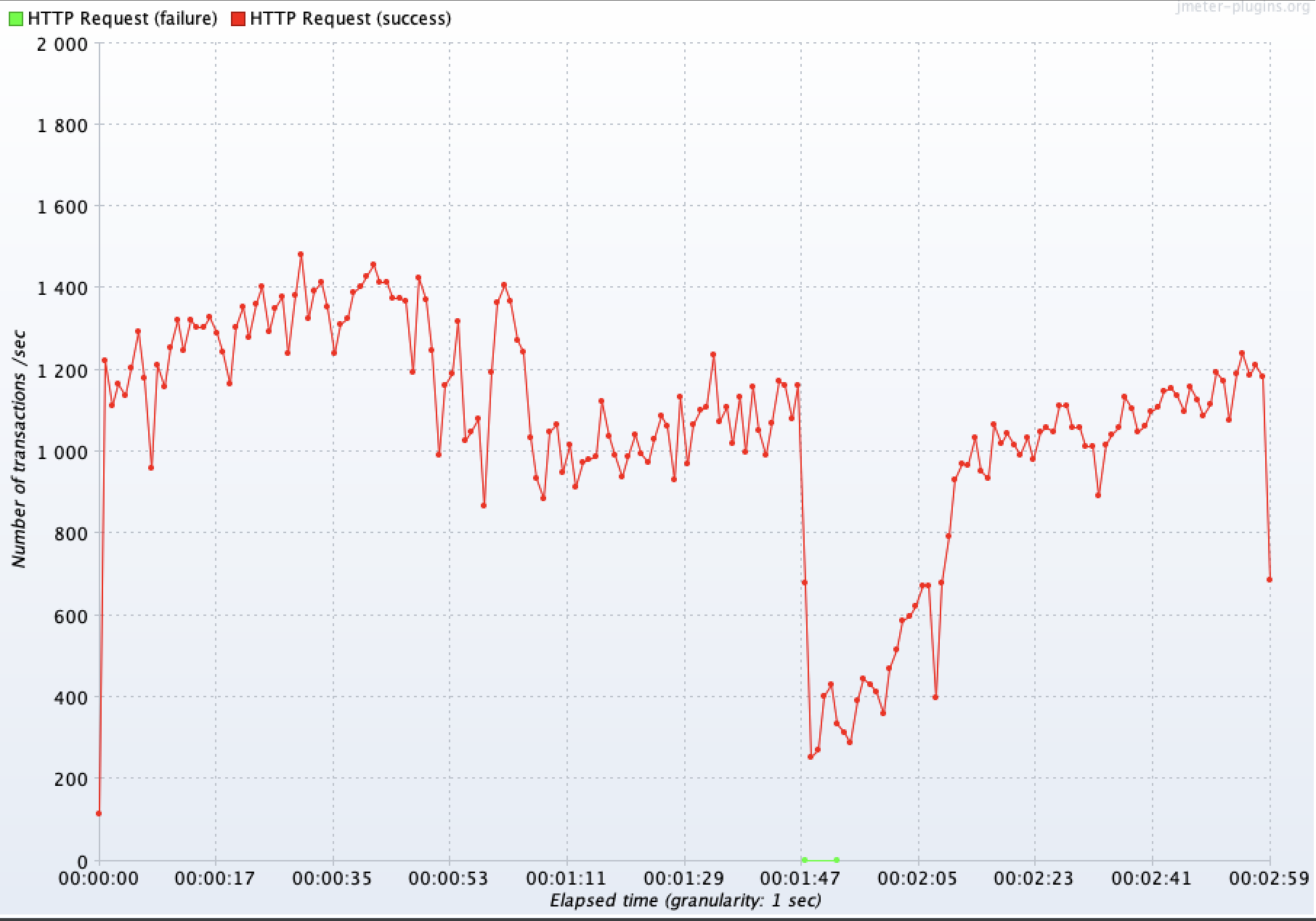
에러를 의미하는 초록색 점이 2번 찍힌 것을 확인할 수 있다. Rolling 배포 시 요청 실패 양상과 달리 단 2번의 순간에 극소수의 요청만 실패했다.

Jmeter에서 해당 시간대 요청들 살펴보니, 단 4개의 요청이 찰나의 순간에 실패한 것을 확인할 수 있었다. 요청 시간을 확인하면 40초 부근에서 3개의 요청, 45초 부근에서 1개의 요청이 실패했다. 이를 통해 2대의 서버 각각에서 0.002초(2ms) 미만의 다운 타임이 발생했다는 것을 확인할 수 있다.
이 방식으로 행동대장 팀은 사실상 무중단 배포를 할 수 있게 되었고, Blue Green 배포이기 때문에 새로 배포하는 버전이 하위 호환을 보장하지 않을 때도 무중단 배포를 할 수 있게 됐다.
주의할 점은 배포 시 하나의 EC2 안에 Tomcat 프로세스 2개를 띄우기 때문에, 동시에 두 개의 프로세스가 동작하는 순간에는 EC2 서버의 자원을 많이 소비한다. TPS를 보면 1200에서 300으로 떨어진 것을 볼 수 있는데, 이 시점이 EC2 내에 WAS 두 대가 동작하는 시점이다. 이런 문제를 해결하기 위해서는 새로운 EC2를 생성해서 별도의 EC2에 새로운 버전을 배포하는 방식으로 해야 하지만, EC2를 종료하는 권한이 없기 때문에 이번 프로젝트에는 적용할 수 없었다.
추가적인 고민
2ms의 다운 타임 정도는 현재 규모의 서비스에서 거의 영향을 주지 않기에 무중단 배포에 성공했다고 결론을 내렸다. ALB를 제어할 권한이 없어서 Nginx를 도입하였는데, 처음에는 단순히 배포만을 위해 Nginx를 사용하는 것에 거부감이 들었다. 하지만 ALB의 Health Check 최소 시간인 5초로 설정하더라도 최소 5초의 다운 타임이 발생하고 최소 체크 횟수 또한 2회로 지정되어 있어 사실상 10초의 다운 타임이 발생하게 되는데, 이를 2ms로 줄일 수 있기에 Nginx 도입이 합리적이라고 생각한다.
다운 타임인 2ms 조차 줄일 방법은 없을까? 배포를 위해 서버가 중단되기 전에 ALB의 Health Check를 선제적으로 Down 처리하여 응답할 수 있다면, 완전한 무중단을 할 수 있을 거로 생각한다. 배포 전에 Nginx 단에서 Health Check에 Down을 응답하는 방법, 애플리케이션에 서버를 Down 상태로 만드는 API를 만드는 방법 등 여러 고민을 했다. 하지만 2ms를 줄이기 위해 구현할 부분과 관리할 범위가 늘어나기에 현재 방식이 합리적이란 결론을 내렸다.
댓글남기기